C++17 終於把 optional 這東西加進標準了,如題 optional 就是個把「有跟沒有」這件事情和「變數內容」打包在一起的萬能懶人包。方便我們判斷一件事是否有結果,開始介紹 optional 用法之前,先來看幾個小情境吧!
不確定找不找得到東西
今天我們想在一個字串 std::string 裡面找到第一個大寫的字元,然後回傳。聽起來很簡單,但問題來了,找不到怎麼辦?最容易的辦法就是,把某個特定的回傳值賦予意義為「沒找到」。
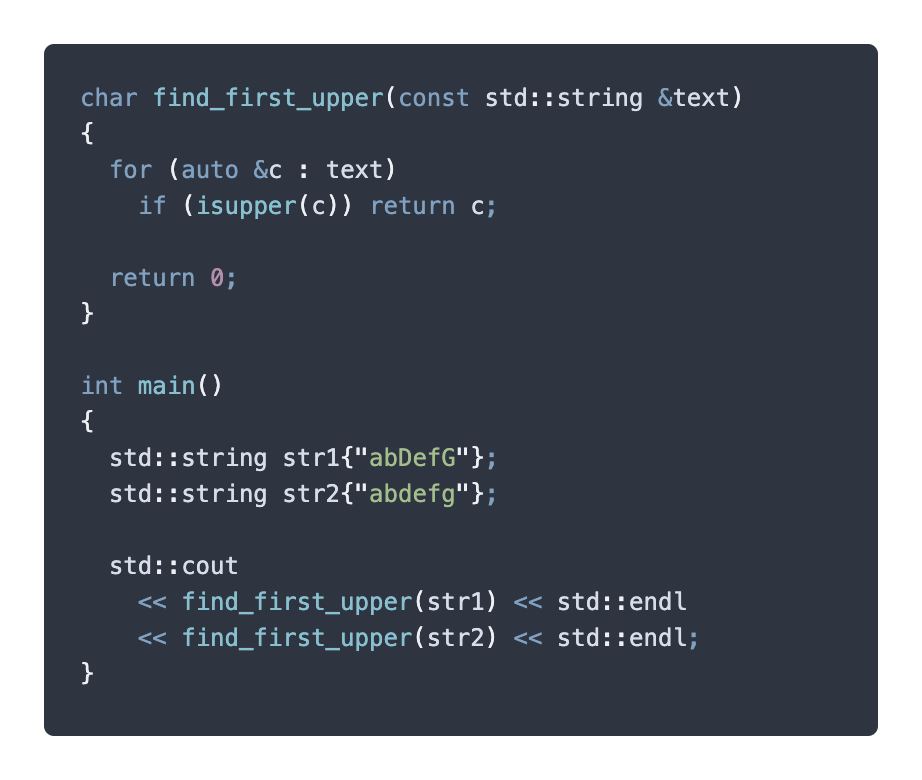
像上面這個 find_first_upper 函式,我們在找不到大寫字元時,回傳 0 代表找不到。這樣的作法明顯的缺點是:對使用函式的人來說語義極度不清,必須有額外的知識學習成本知道某個特定的回傳值的意涵。而且和回傳值本身的型別語義上也不太恰合。可能造成使用函式的開發者誤用。
用回傳值代表成功與否
另個方法是,用 bool 回傳值代表成功或 GG。但結果就放在函式參數用引用/參照的方式傳入,由函式內修改。

函式的使用者可以很輕易地使用 find_first_upper() 的回傳值做為業務成功的判斷基準,然而,可是,but,雞蛋裡挑骨頭,小問題是參數多了一個人。
而且對使用者來說,他必須花成本學習區分哪些參數是入參 (輸入) 哪些是出參 (輸出)。如果我們今天的輸出不只一個字元,還包含了一個位置訊息,那日後這個函式可能要傳越來越多參數,不太美觀,很不舒服。
通通包起來
第三階段的進化,也可以把成功與否,大寫字元,位置等訊息通通包在一個結構裡面回傳,大概用法就進化成這樣

對於 find_first_upper() 的使用者來說,只要判斷 struct find_result 這個結構的 succ 成員就知道成功與否,並且可以從這個結構中讀出大寫字元和位置。
唯一剩下的缺點就是,要自己指定 succ 成功了很煩瑣,容易手殘忘記。而且如果我們有很多不同的業務邏輯函式需要判斷成功與否,我們都要自己包一個 struct 結構嗎?
我們的 C++ 標準委員會終於在 7102 年幫同學們想到了這點,在 C++ 標準庫裡面引入了泛型的包裝方法,可以包羅萬象地把各種型別的資料打包起來,也就是今天的主題 std::optional。
標準庫泛型包裝 std::optional
C++17 的 std::optional<T> 是一個型別樣版類別,型別 T 就是你要包裝的型別。可以通過 #include <optional> 看到他。
基操
不囉嗦直接上 code 就知道怎麼用了。
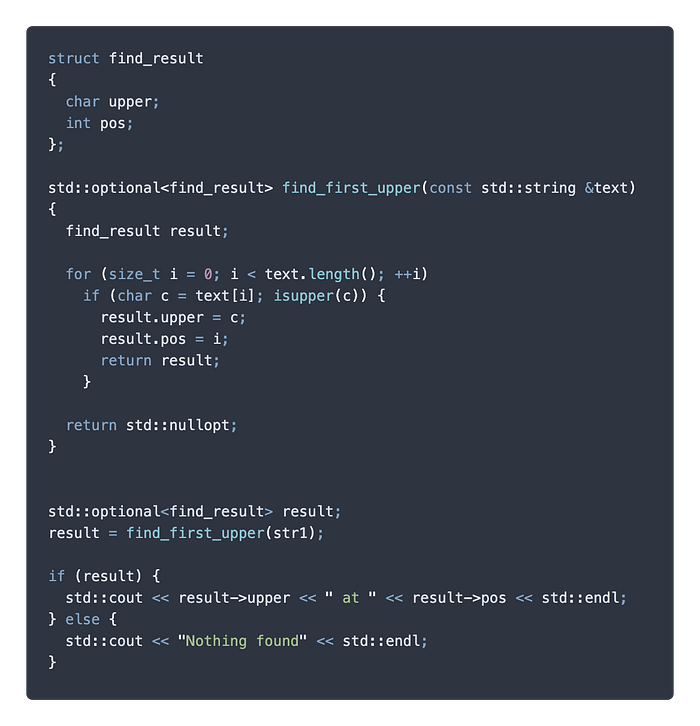
相較於前面上古的作法,現代我們在 find_first_upper() 裡一樣在找到大寫字元時對 find_result 的內容賦值,並且回傳 ,這時 std::optional 的建構式就會把我們的 find_result 結構吃起來構造出 std::optional<find_result>。那麼,和上古時代不同的是
- 不需要自己指定成功與否,在使用的地方,直接用
if判斷optional是否有值就可,方便簡潔美妙。
想讓語義更加明確的同學可以使用result.has_value(),是一個意思。 - 標準庫提供了地位類似於
nullptr的std::nullopt,明確代表沒有值的optional物件。這物件在if中會被視為false沒有包裝值。
想寫少一點字的同學可以直接return {}構造空的optional。 - 使用時,如同我們使用 iterator 一樣,用
->或是*就可以取到包裝內容物。 find_first_upper()函式本身除了回傳值型別的標示以外,都和optional沒有關係,十足保留了原有單純的業務邏輯語義。
想要原地 (in-place) 打包物件
上面的找大寫字元 find_first_upper() 函式,我們先做出個一個 find_result 物件才把成員賦值回傳構造成 optional<find_result>。
如果想要更簡單一點,標準庫提供了你就地成佛打包物件的方法,利用 std::in_place 這個參數標示在 optional 的 constructor 原地打包,就可以完成類似 std::vector 的 emplace_back() 的效果。
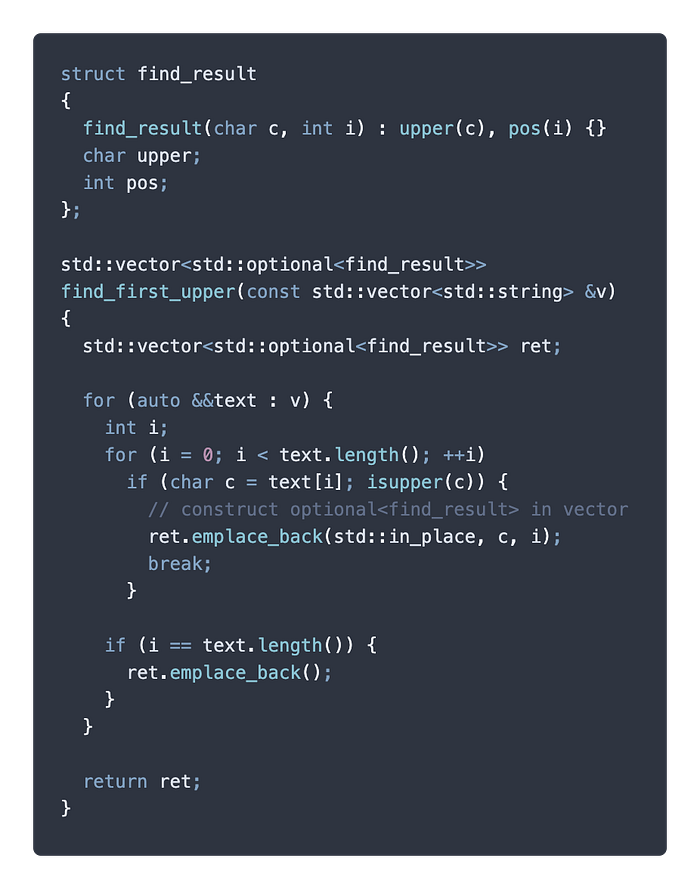
這個例子中小小改了一下 find_first_upper() 讓他變成用途是一次找很多字串的大寫字元。我們可以看到我們在回傳值 vector 使用 emplace_back() 加上 std::in_place 直接在 vector 裡面做出一個 optional 打包後物件。
打包時的魔鬼細節
通常我們可以很自然地把 optional 當作一個透明的代理層去初始化打包 T 進去。比如
optional<int> opt = 10; // copy-construction但對於那些標示著 explicit constructor 的型別就不能這樣子搞,你各位看看這個情況

代碼中的的 sumT() 可以在呼叫時將 20 用來初始化 optional<T>。但是被註解掉的那行 sumS() 就不行,為何?因為 S 的 constructor 掛上 explicit 了。
但你說我 S 有 explicit ctor 跟我 optional<S> 有什麼關係?還真有關係,因為 optional 實作了 conditionally explicit,當我們想打包型別 S 對應的 ctor 掛上了 explicit,那 optional<S> 的 ctor 就會是 explicit。想看更多這個機制詳細可以看這一篇介紹:C++20 的 explicit (bool)。
配菜們 / optional 的小夥伴函式
除了上面的-> 或是 *可以取到打包的內容物以外,我們可以使用 value() 語義更明確地拿到內容物。
假設我們正在撰寫一個接收客戶端請求的服務端。需要從請求讀入一個一個欄位,有的客戶端有給值,有些欄位沒有值,我們需要給定一個預設值。 這時候我們可以使用 value_or() 代表一個 optional 物件的預設內容物。
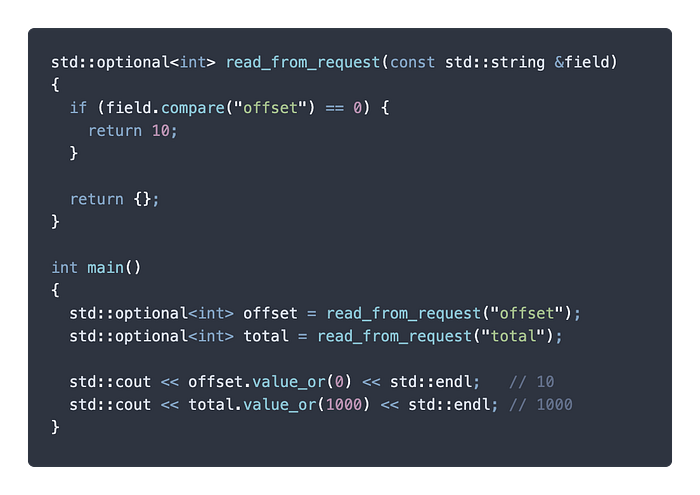
上面這個例子應該很好理解,offset 是有給值的 optional 所以印出 10 ,而 total 是空 optional,所以 value_or() 回傳印出 1000。
value_or() 的魔鬼細節
value_or(u) 給定的預設值什麼都可以給嗎?當然不行,為了滿足「 optional<T> 包裝了型別 T 」的語義,value_or(u) 的參數 u 必須可以初始化型別 T,或是可轉型成 T。
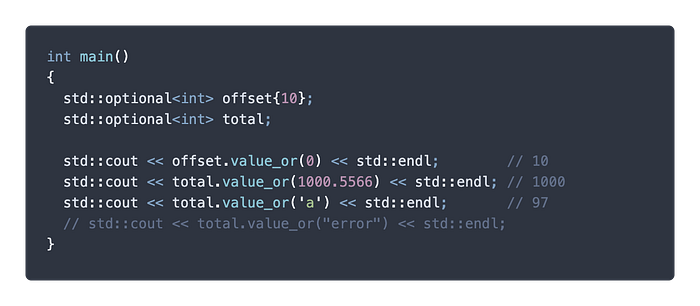
因為 1000.5566 (double) 還有 ‘a’ (char) 可以轉型成 int,所以順利印出 1000 和 97 沒問題。但假設我們想要給定預設值是一個錯誤訊息?抱歉那真的就是個錯誤了,因為 const char* 沒辦法轉型成 int。
大開腦洞,特殊用法
optional 的 T 理論上可以放天上飛的地下爬的有的沒的型別,所以我們開幾個腦洞講講以下幾種使用情境,告訴大家:
不要這樣用。
optional<bool>
語法上完全合理,我想要打包一個 bool 變數,可能有,可能沒有,不好嗎?
不好,很糟。
因為 optional 語義上就是代表一個有或沒有的意涵,如果你拿來包一個 bool,那不就是自己互相打架嗎,你自己可能看得懂,但代碼的維護者,對你的同事,你的小夥伴來說可能不是這回事。下面這個情況
optional<bool> opt{false};if (opt) {
// Yes, I have a bool value.
}if (!*opt) {
// I have a bool value, but I'm false.
}
你等於是有了一個三種狀態的 bool,同學們人生已經如此艱難,請不要把事情弄得更加複雜。
optional<T*>
我們也可以把指標丟進去 optional 裡面,對於指標也是類似的道理,語義會變得十分不清
optional<int*> my_int1{ new int[1024] };if (my_int1) {
std::cout << Yes, I have allocated memory.\n";
}optional<int*> my_int2{ nullptr };if (my_int2) {
std::cout << "I have allocated memory...!!!???\n";
}
不要這樣用,很尷尬。
optional<shared_ptr<T>> / optional<unique_ptr<T>>
跟指標同個道理,不要這樣用,很北爛。
跟我自己打包還有差別嗎?
你說 optional<T> 是個包羅萬象包泛型的樣版類別,那我自己寫一個像這樣的 my_optional<T> 長這樣有什麼不一樣嗎?
template<typename T>
struct my_optional
{
bool has_value;
T value; my_optional() : has_value{false} {}
};
不同的地方不少,仔細看下去會發現皮毛很多。
這樣實作第一是 has_value 和 value 的記憶體對齊問題,C++ 標準規定了必須把標示有無值的變數跟存放 T 的記憶體對齊。不過因為對齊的關係,基本上 optional<T> 的記憶體用量會是 T 的兩倍之多,這點同學們要多多注意。
第二是 my_optional 在實例化時,無可避免一定要把 T 也一起呼叫預設 constructor 給實體化,如果說你的 T 沒辦法預設實例化 (比如沒有無參數的 constructor),那你就會得到編譯器報錯。
而 std::optional 只在你對物件賦值打包的時候才會實體化做出真的 T。原理是底層包了一個 union 把一個另個內部小變數和 T 放在一起。
更重要的是,如果你的 T 的 constructor 操作比較厚重 (比如連線一個 SQL DB 做點 query,或是要求一些記憶體資源,比如下面這個
struct find_result
{
find_result() {
s.resize(1024);
} vector<string> s;
};
光是做出 50000 個這樣的 my_optional 物件,就是天和地的效率差距了…
int main()
{
auto st1 = clock();
for (int i = 0; i < 50000; i ++) {
my_optional<find_result> opt;
}
auto ed1 = clock(); auto st2 = clock();
for (int i = 0; i < 50000; i ++) {
optional<find_result> opt;
}
auto ed2 = clock(); std::cout
<< 1. * (ed1 - st1) / CLOCKS_PER_SEC << ", "
<< 1. * (ed2 - st2) / CLOCKS_PER_SEC << std::endl;
}
在我的電腦上執行的效率是這樣的… 228 倍的時間差距啊!
3.65101, 0.001627講完了
這期內容其實很簡單,用起來也簡單,但實際上鑽研一點細節才會發現其實C++ 標準庫在實作上考慮的東西也是很多。好不容易出了這個 std::optional,考量到效率也考量到保持各種語義還有簡潔寫法才有這麼精良的成果。同學們就加減用一下。也不是到處都 optional,該例外處理的還是該丟例外,該用錯誤碼的還是錯誤碼表示判斷,好好處理異常情況 XD。也不要把奇奇怪怪的東西,比如 bool,指標丟進去,造成語義混淆頭腦混亂。
